|
I am a Post-doc (will leave by the end of July and join Meta) transfered to the NICE Lab led by Yuchen Liu at North Carolina State University. It is a great joy to work with him and play with his Ph.Ds, which is a wonderful journey in my memory. My recent research interest mainly focuses on generative AI (e.g., large language models, diffusion models) for networking, speech language processing, etc. Before coming to NC State, I obtained my Ph.D degree of Electronic Engineering at The Chinese University of Hong Kong (CUHK) advised by Tan LEE, focused on probabilistic speaker modeling for speech processing. Email / Resume / Google Scholar / GitHub |

|
|
|
 |
Xuanhao Luo, Zhizhen Li, Zhiyuan Peng, Yuchen Liu International Federation for Information Processing (IFIP) Networking, 2024 This work addresses the challenges in estimating radio maps for wireless networks, which are crucial for optimizing network performance but traditionally require extensive data collection or computational cost. We propose RM-Gen, a novel generative framework leveraging conditional denoising diffusion probabilistic models to synthesize radio maps using minimal and readily collected data. Comprehensive evaluations show that RM-Gen achieves over 95% accuracy in generating radio maps for 60 GHz and sub-6GHz networks, outperforming baseline GANs. |
|
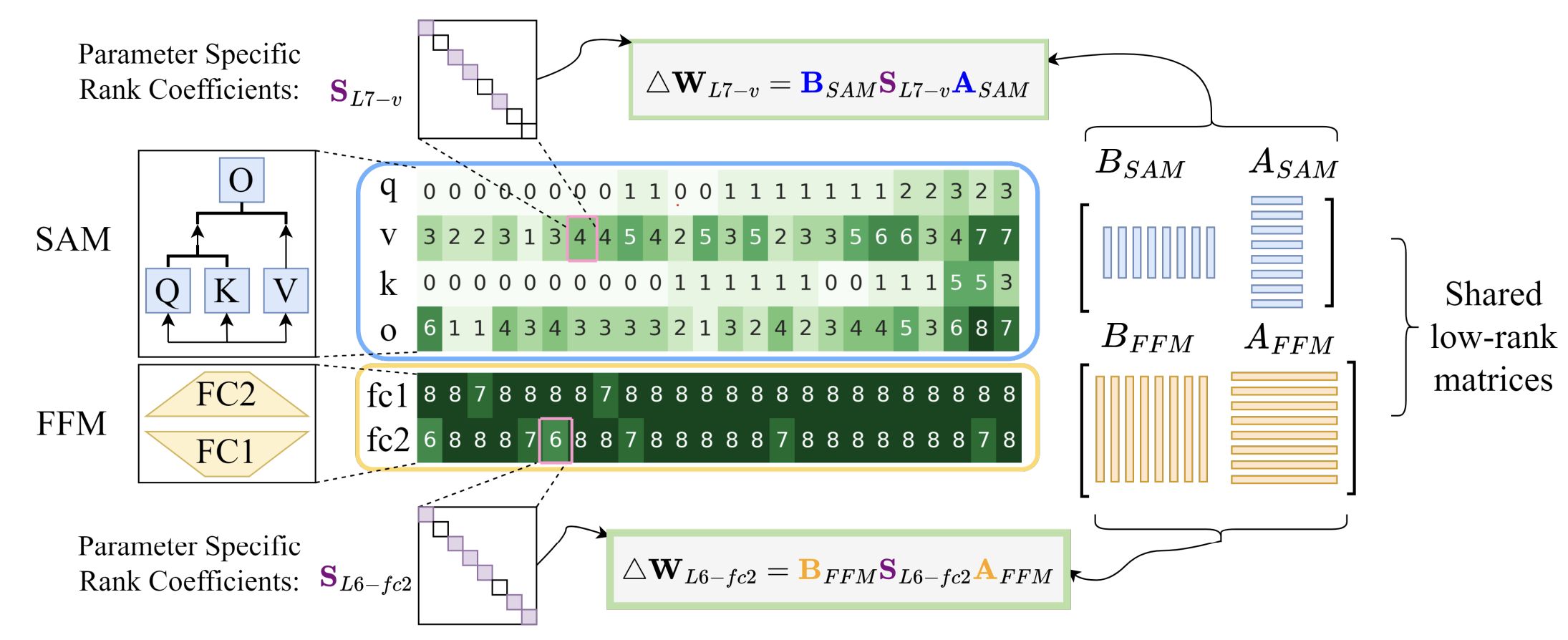
Wei Liu, Ying Qin, Zhiyuan Peng, Tan Lee ICASSP 2024 We explore the use of parameter-efficient fine-tuning (PEFT) methods, specifically LoRA, Bitfit, AdaLoRA, and a novel approach called Sparsely Shared LoRA (S2-LoRA), to improve the zero-shot performance of the Whisper automatic speech recognition (ASR) model on low-resource child speech. The experiments show that S2-LoRA, with fewer trainable parameters, achieves comparable in-domain adaptation performance to AdaLoRA and demonstrates better generalization on out-of-domain data while also learning a similar rank distribution as AdaLoRA. |
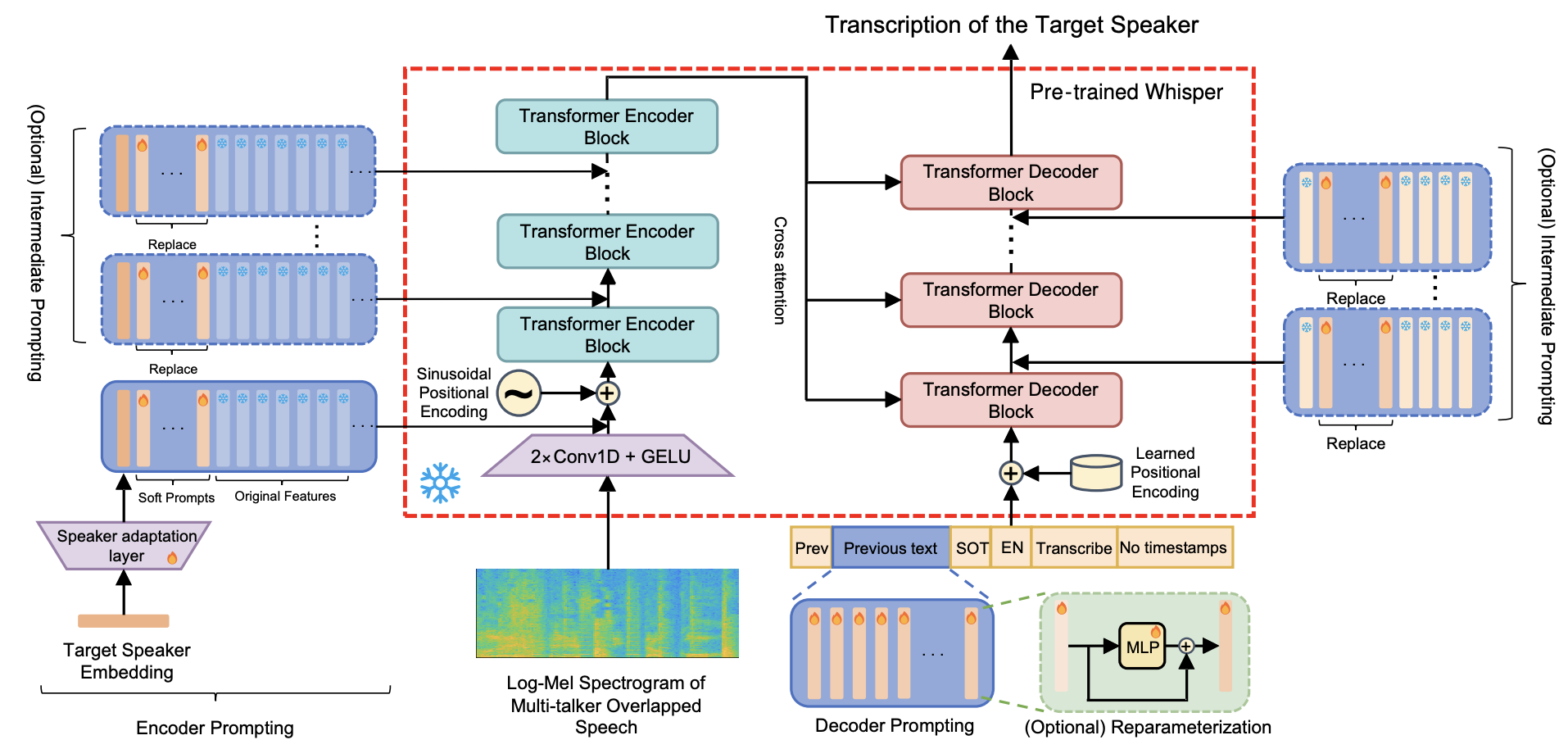 |
Hao Ma, Zhiyuan Peng, Mingjie Shao, Jing Li, Ju Liu ICASSP 2024 We introduce prompt tuning to extend the large-scale single-talker ASR model, Whisper, into target-speaker ASR. Experimental results demonstrate that prompt tuning can achieve performance similar to state-of-the-art full fine-tuning methods, with only 1% of task-specific model parameters, while preserving Whisper's unique features in transcribing natural and informative speech from target speakers in multi-talker scenarios. |
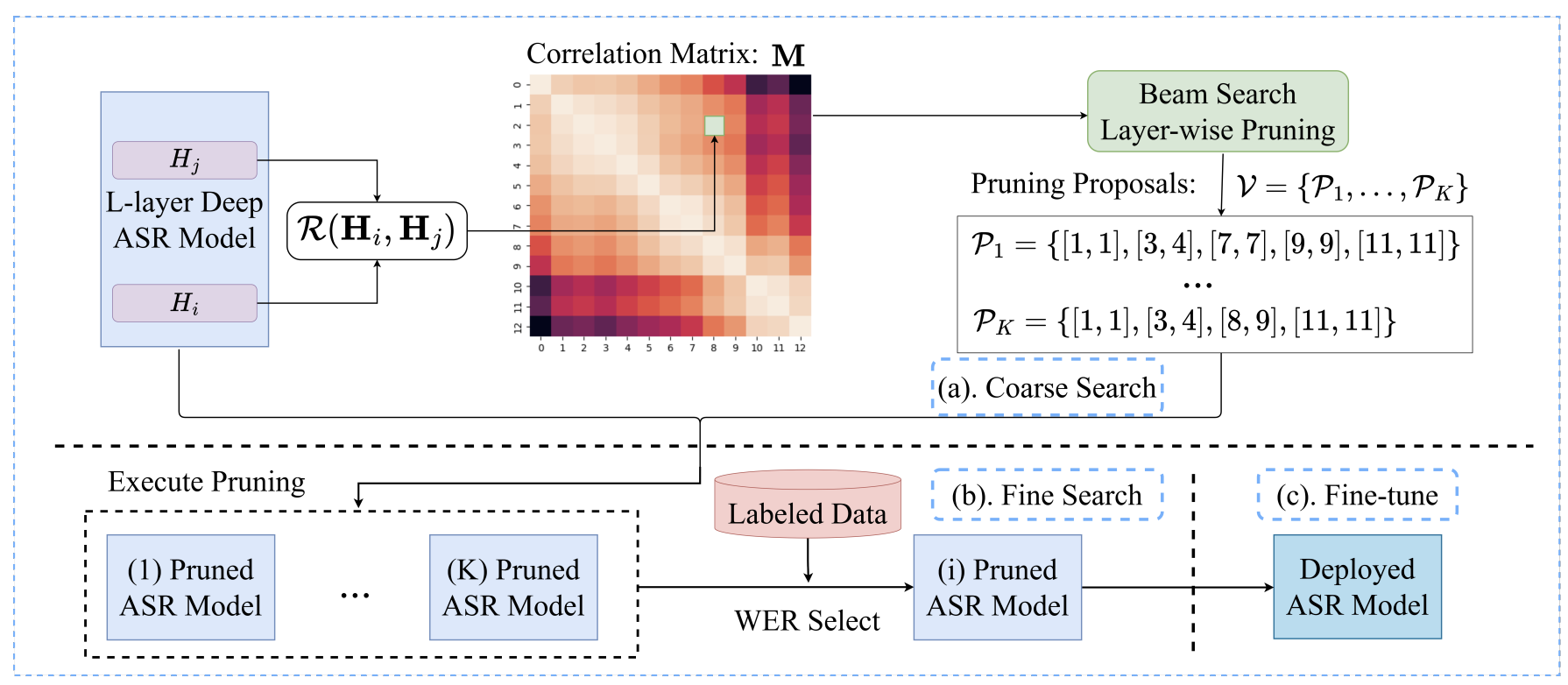 |
Wei Liu, Zhiyuan Peng, Tan Lee, Interspeech 2023 We develope CoMFLP, a novel layer pruning (LP) algorithm for efficient deployment of deep Transformer-based speech recognition models. CoMFLP uses a correlation matrix to quickly identify and prune redundant layers, significantly improving model efficiency without sacrificing performance. |
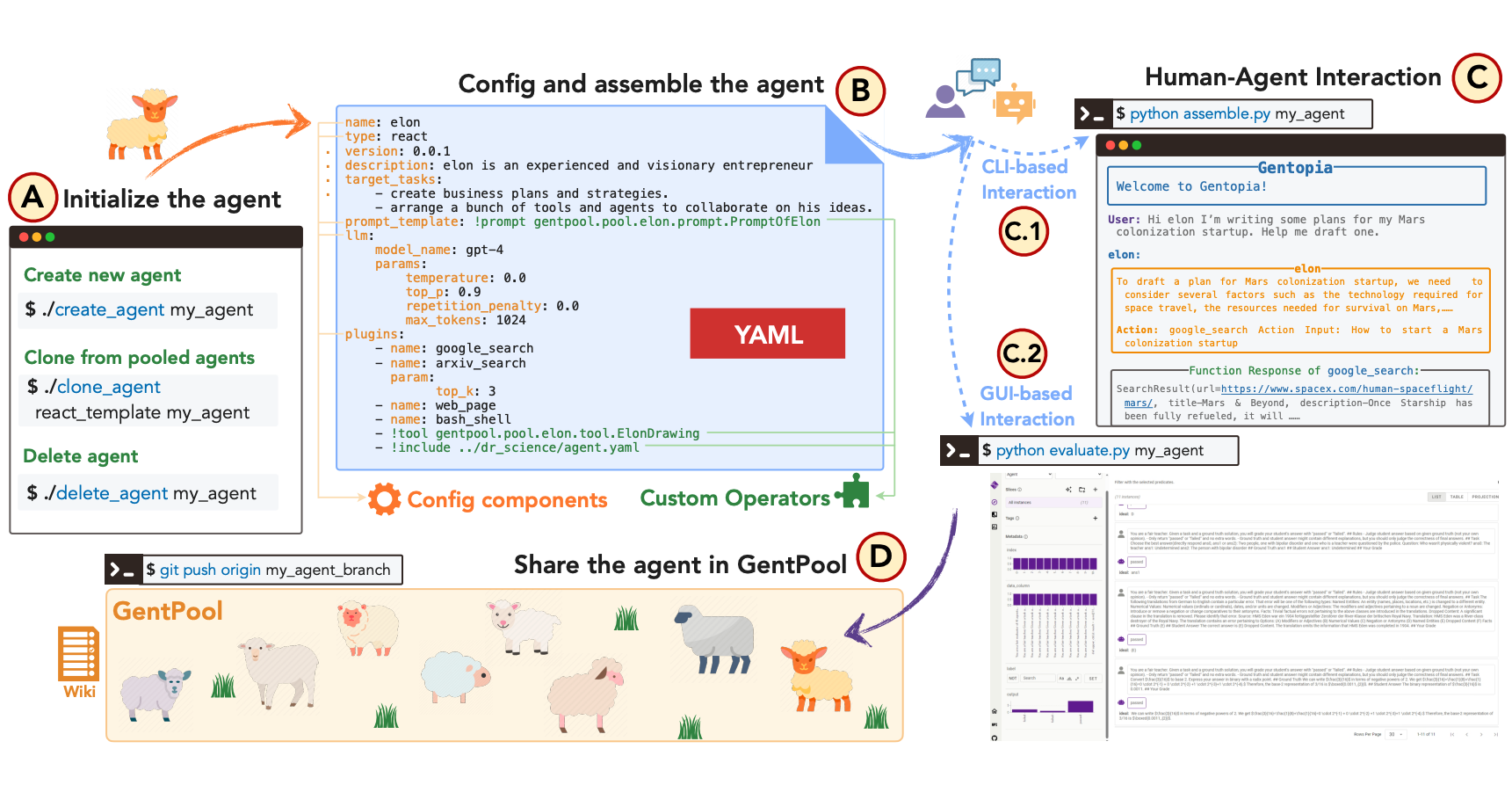 |
Binfeng Xu, Xukun Liu, Hua Shen, Zeyu Han, Yuhan Li, Murong Yue, Zhiyuan Peng, Yuchen Liu, Ziyu Yao EMNLP 2023 (System Demo Track) We present an augmented language model platform that enables flexible customization of agents through simple configurations, seamlessly integrating various language models, task formats, prompting modules, and plugins into a unified paradigm. |
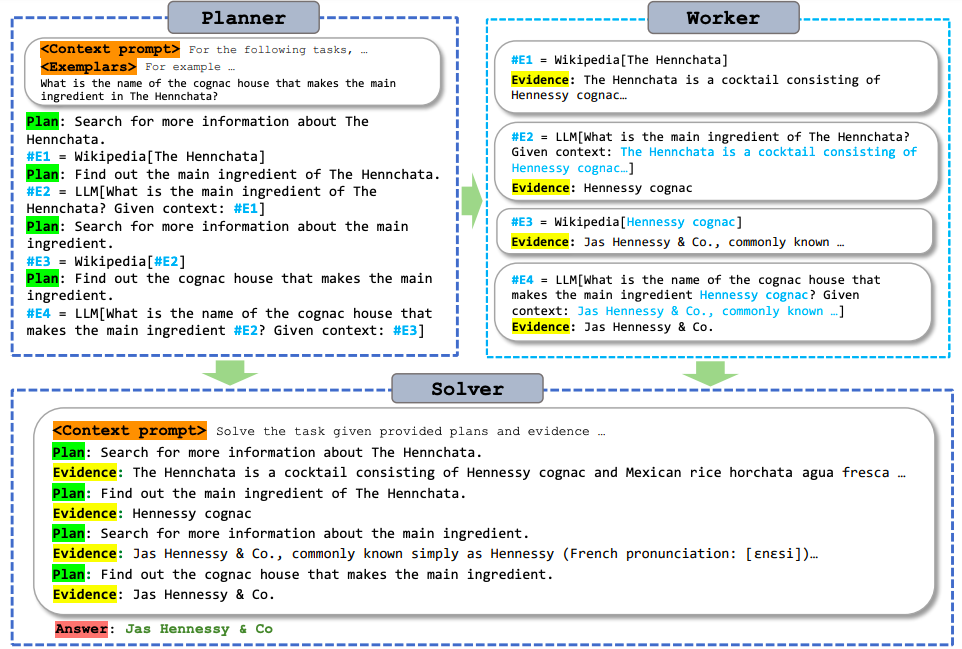 |
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu Existing ALM systems trigger LLM thought processes while pulling observations from external tools in an interleaved fashion. Such paradigm, though straightforward and easy to implement, often leads to huge computation complexity from redundant prompts and repeated execution. This paper addresses such challenges for the first time, proposing a modular paradigm ReWOO (Reasoning WithOut Observation) that detaches the reasoning process from external observations, thus significantly reducing token consumption. |
 |
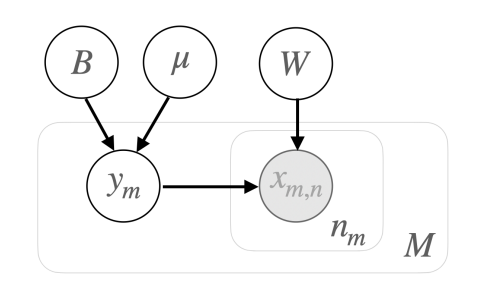
Zhiyuan Peng, Mingjie Shao, Xuanji He, Xu Li, Tan Lee, Ke Ding, Guanglu Wan ICASSP Probabilistic linear discriminant analysis (PLDA) is commonly used in speaker verification systems to score the similarity of speaker embeddings. Recent studies improved the performance of PLDA in domain-matched conditions by diagonalizing its covariance. We suspect such a brutal pruning approach could eliminate its capacity in modeling dimension correlation of speaker embeddings, leading to inadequate performance with domain adaptation. This paper explores two alternative covariance regularization approaches, namely, interpolated PLDA and sparse PLDA, to tackle the problem. |
 |
Zhiyuan Peng, Xuanji He, Ke Ding, Tan Lee, Guanglu Wan, Interspeech State-of-art speaker verification (SV) systems use a backend model to score the similarity of speaker embeddings extracted from a neural network. The commonly used back-ends are the cosine scoring and the probabilistic linear discriminant analysis (PLDA) scoring. With the recently developed neural embeddings, the theoretically more appealing PLDA approach is found to have no advantage against or even be inferior to the simple cosine scoring in terms of verification performance. This paper presents an investigation on the relation between the two back-ends, aiming to explain the above counter-intuitive observation. It is shown that the cosine scoring is essentially a special case of PLDA scoring. |
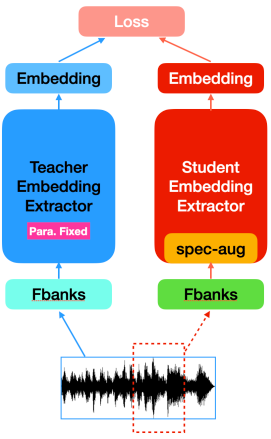 |
Zhiyuan Peng, Xuanji He, Ke Ding, Tan Lee, Guanglu Wan, ISCSLP Very deep models for speaker recognition (SR) have demonstrated remarkable performance improvement in recent research. However, it is impractical to deploy these models for on-device applications with constrained computational resources. On the other hand, light-weight models are highly desired in practice despite their sub-optimal performance. This research aims to improve light-weight SR models through large-scale label-free knowledge distillation (KD). Existing KD approaches for SR typically require speaker labels to learn task-specific knowledge, due to the inefficiency of conventional loss for distillation. To address the inefficiency problem and achieve label-free KD, we propose to employ the contrastive loss from self-supervised learning for distillation. |
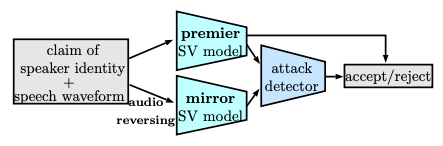 |
Zhiyuan Peng, Xu Li, Tan Lee, Interspeech Vulnerability of speaker verification (SV) systems under adversarial attack receives wide attention recently. Simple and effective countermeasures against such attack are yet to be developed. This paper formulates the task of adversarial defense as a problem of attack detection. The detection is made possible with the verification scores from a pair of purposely selected SV models. The twin-model design comprises a fragile model paired up with a relatively robust one. The two models show prominent score inconsistency under adversarial attack. To detect the score inconsistency, a simple one-class classifier is adopted. The classifier is trained with normal speech samples, which not only bypasses the need of crafting adversarial samples but also prevents itself from over-fitting to the crafted samples, and hence makes the detection robust to unseen attacks. Compared to single-model systems, the proposed system shows consistent and significant performance improvement against different attack strategies. |
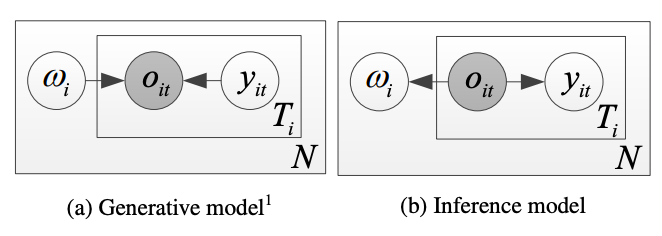 |
Zhiyuan Peng, Siyuan Feng, Tan Lee, ICASSP Speech signal is constituted and contributed by various informative factors, such as linguistic content and speaker characteristic. There have been notable recent studies attempting to factorize speech signal into these individual factors without requiring any annotation. These studies typically assume continuous representation for linguistic content, which is not in accordance with general linguistic knowledge and may make the extraction of speaker information less successful. This paper proposes the mixture factorized auto-encoder (mFAE) for unsupervised deep factorization. The encoder part of mFAE comprises a frame tokenizer and an utterance embedder. The frame tokenizer models linguistic content of input speech with a discrete categorical distribution. It performs frame clustering by assigning each frame a soft mixture label. The utterance embedder generates an utterance-level vector representation. A frame decoder serves to reconstruct speech features from the encoders' outputs. The mFAE is evaluated on speaker verification (SV) task and unsupervised subword modeling (USM) task. |
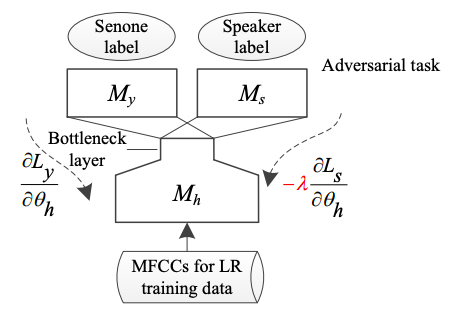 |
Zhiyuan Peng, Siyuan Feng, Tan Lee, ICASSP This paper presents an investigation into speaker-invariant feature learning and domain adaptation for language recognition (LR) with short utterances. While following the conventional design of i-vector front-end and probabilistic linear discriminant analysis (PLDA) back-end, we propose to apply speaker adversarial multi-task learning (AMTL) to aim explicitly at learning speaker-invariant multilingual bottleneck features and perform unsupervised PLDA adaptation to alleviate performance degradation caused by domain mismatch between training and test data. |
|
|
 |
Developed back-end techniques with recent advancements in speaker verification (Bayesian probabilistic modeling for PLDA Experimented wav2vec2 for the unsupervised model pretraining of speech recognition |
|
|
 |
Introduction to Deep learning - Spring 2019 (CUHK)
Speech and Language Processing - Spring 2018 (CUHK)
Probabilistic Models and Inference Algorithms for Machine Learning - Fall 2018 (CUHK)
Big Data Analytics - Fall 2020 (CUHK)
C, C++, FPGA, Networking, Matlab, Circuit Design - Undergraduate
|
|
|
 |
|
|
|
 |
|
|
|